Research Areas
Our current research span three broad areas and often integrates all three:
- Machine Learning and Deep Learning
- Natural Language Processing
- Computational Logic (including Higher-Order Logic) and Reasoning
Current and Potential Project Themes
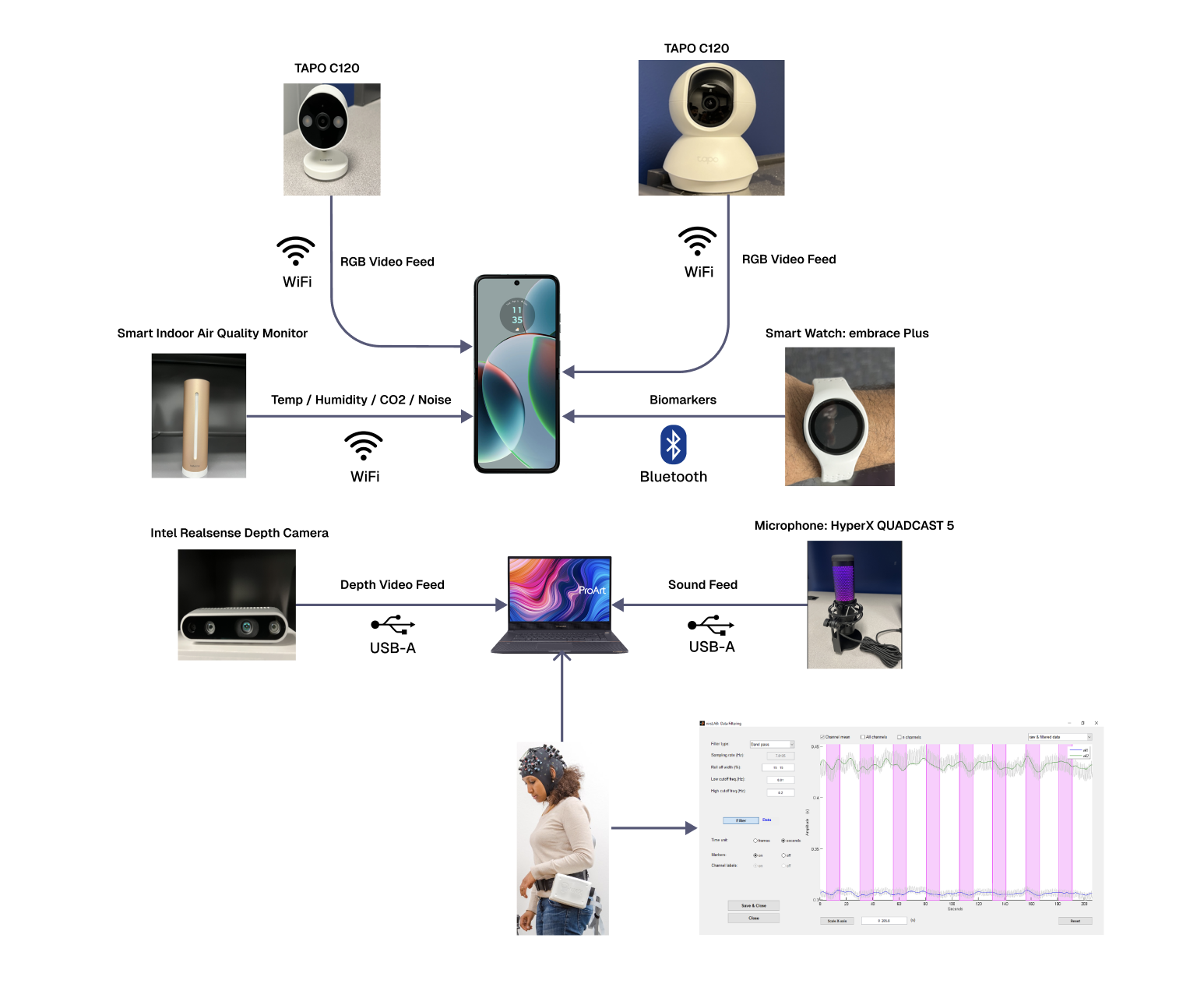

We are building a human‑centric, hybrid‑AI system to understand and predict behavioral patterns in 2–5 year‑old children with ASD, bridging communication between caregivers and children through personalized, evidence‑based insights. The system fuses multimodal data—day‑to‑day audio/video, environmental context, and physiological signals (e.g., electrodermal activity)—together with ABA therapist and clinical reports for longitudinal evaluation. Early experiments show facial expressions alone are ambiguous, so we prioritize truly multimodal sensing and are partnering with ABA centers in the New Orleans and greater Louisiana area to collect data using cameras (including depth), high‑quality microphones, air monitors, and wearable sensors.
.png)
.jpg)
We evaluate small vision-language models (Gemma-3 and Qwen-VL) on qualitative mechanical problem solving — a key component of human commonsense reasoning. Using benchmark tasks from the Bennett Mechanical Comprehension Test, we analyze not only model accuracy but also the quality of their step-by-step reasoning. Results show that while both models can arrive at correct answers, their reasoning often contains flaws, hallucinations, or poor spatial understanding. This study highlights the need for hybrid, neuro-symbolic systems that integrate visual grounding with formal reasoning to achieve reliable, human-like problem solving.
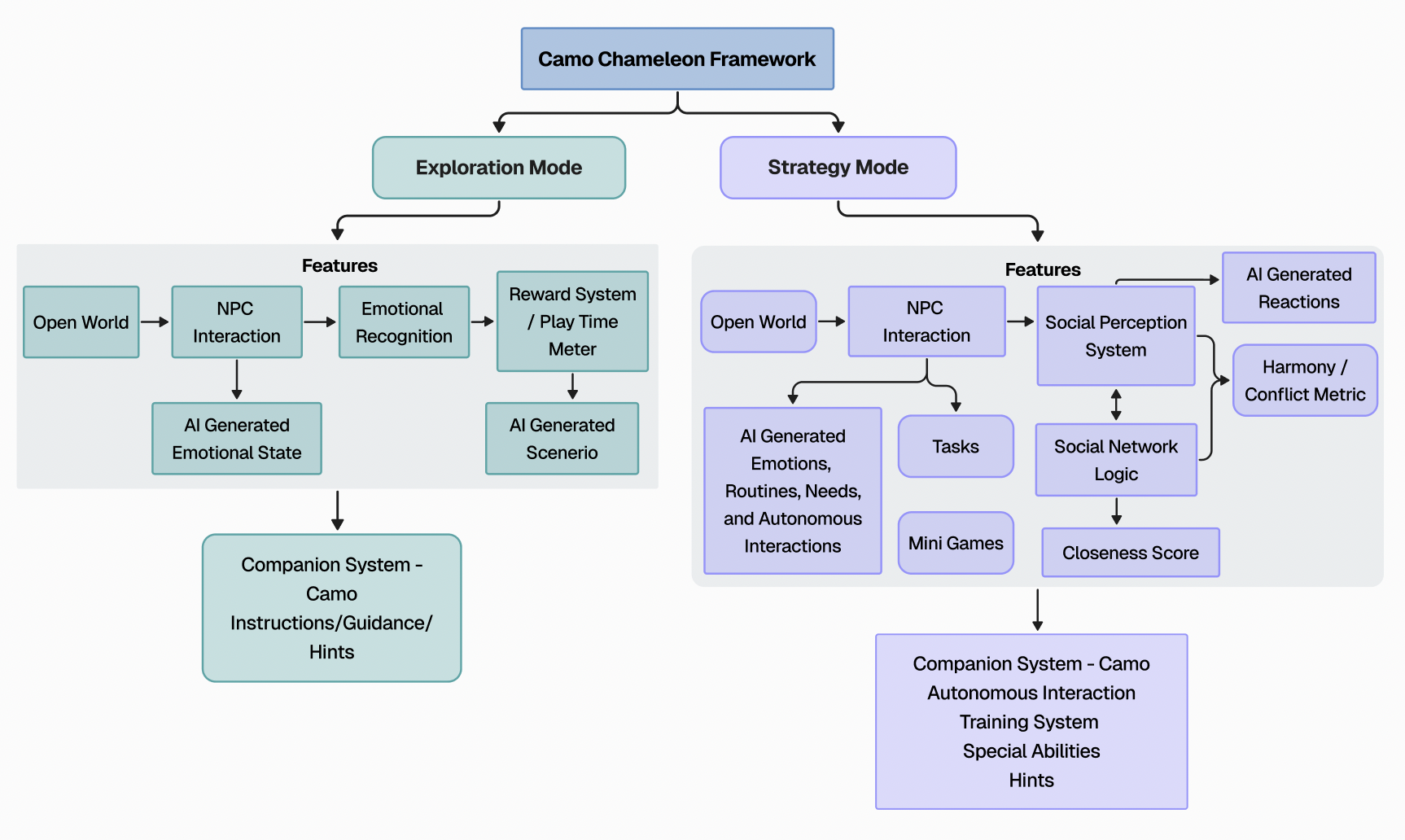
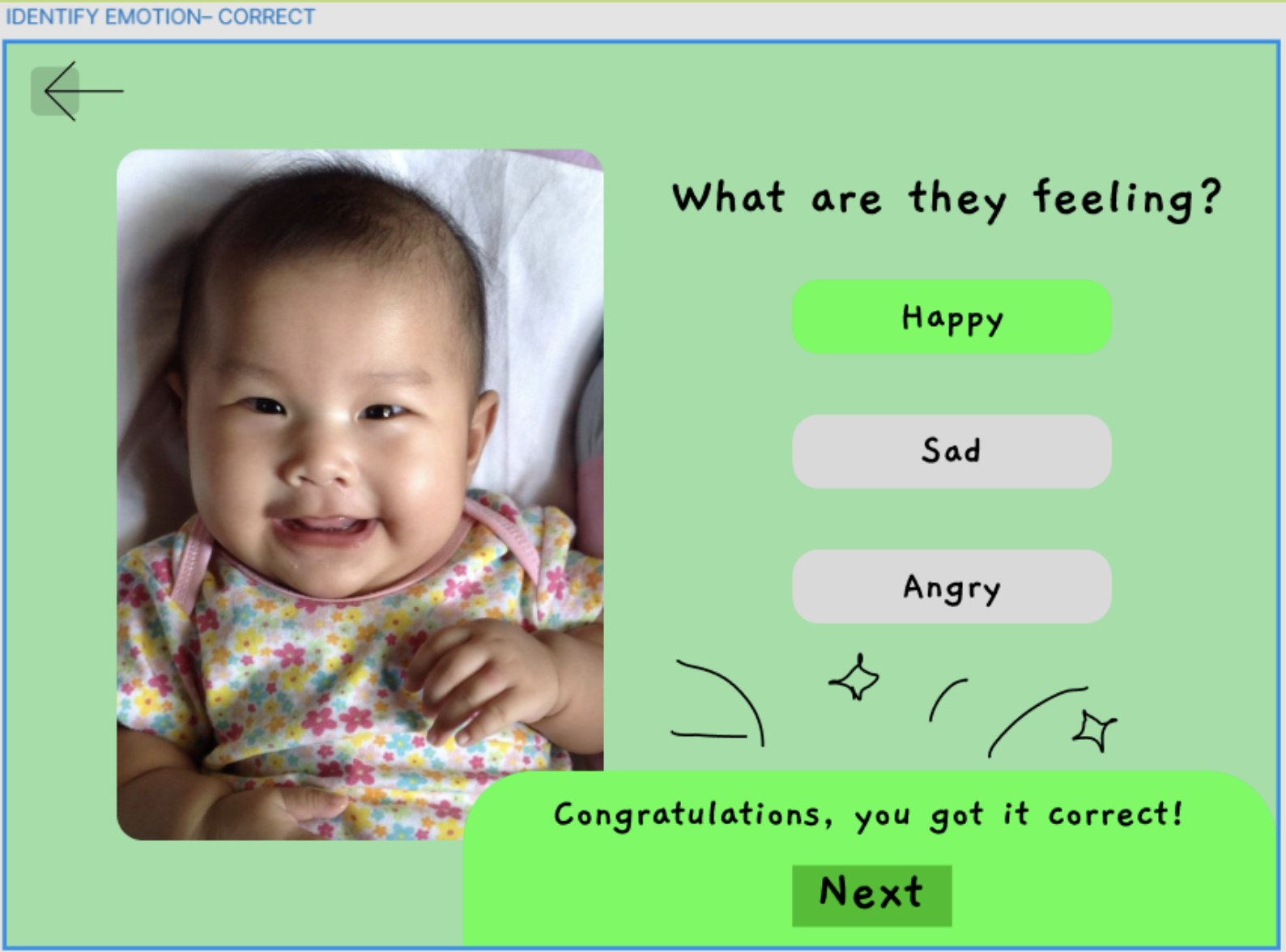
Short description coming soon.

Short description coming soon.
Funding
- Louisiana Biomedical Research Network (LBRN) summer research award, Summer 2024, PI Dr. Shreya Banerjee, Data Collection and Analysis for Enhancing Autism Care and Support through AI-Powered Personalized Behavior
- Louisiana Department of Health research award, 2025-2027, PI Dr. Shreya Banerjee,Enhancing Autism Care and Support through AI-Powered Personalized Behavior Insights in Children with ASD